Notations
Database size: $N$
Plaintext modulus:$p \in \mathbb{N}$. In SimplePIR, $\log(p) \leq 10$.
Ciphertext modulus: $q \in \mathbb{N}$. In SimplePIR, $\log(q) = 32$.
LWE Dimension: $n = 1024$
LWE secret vector: $\vec{s} \in \mathbb{Z}_q^{n}$.
LWE enc factor: $\Delta = q / p$.
LWE Randomized matrix $A \gets \mathbb{Z}_q^{m \times n}$, where $m$ is the number of samples you want to encrypt.
Plain message vector: $\vec{\mu} \in \mathbb{Z}_p^m$. In simplePIR, we also write $\mu_i$ to denote the vector with all zero entries except a single $1$ at index $i$.
LWE Revisit
Regev’s LWE-based encryption scheme:
$$ \begin{align*} \mathsf{Enc}(\vec{\mu}) = (c_1, c_2) &= (A, A \cdot \vec{s} + \vec{e} + \Delta \vec{\mu})\\ \mathsf{Dec}(c_1, c_2) &= \frac{\mathsf{round}_{\Delta}(c_2 - c_1 \cdot \vec{s})}{\Delta}\\ \end{align*} $$SimplePIR
High-level: parse the database into $\sqrt N \times \sqrt N$ square, then use matrix-vector multiplication to retrieve one column. Upload and download size are both $\sqrt N$ many $\mathbb{Z}_q$ elements.
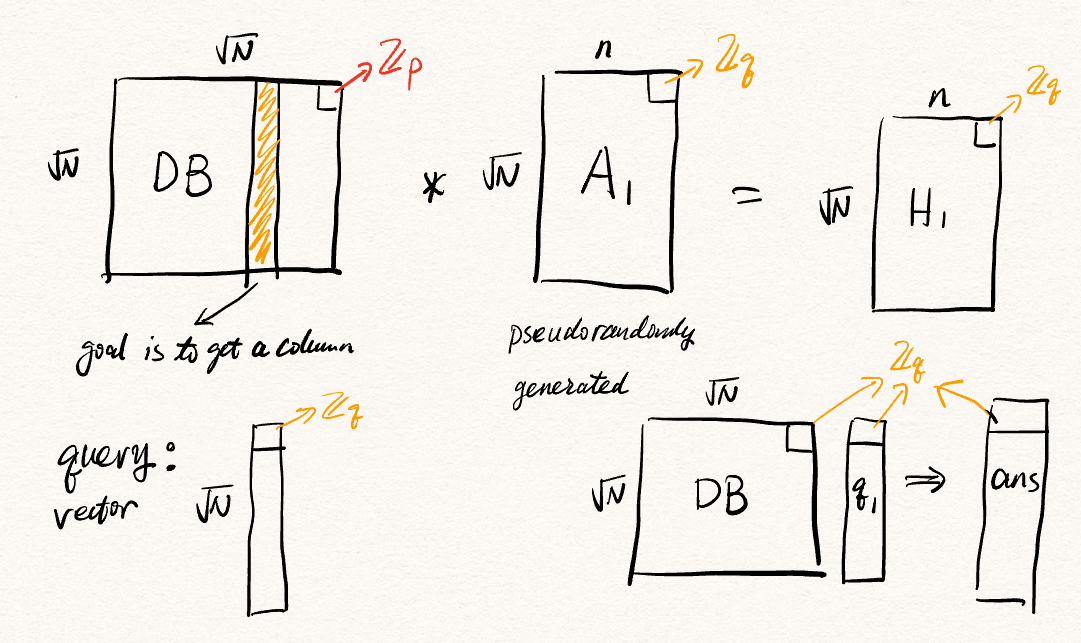
We can recover the whole column:
$$ \begin{align*} \vec{d'} &= \mathsf{ans} - \mathsf{H} \cdot \vec{s}\\ &= \mathsf{DB} \cdot \vec{\mathsf{q_1}} - (\mathsf{DB} \times A) \cdot \vec{s}\\ &= \mathsf{DB} \cdot (A\cdot \vec{s} + \vec{e} + \Delta \vec{\mu_i}) - \mathsf{DB} \times A \cdot \vec{s}\\ &= \mathsf{DB} \times A\cdot \vec{s} + \mathsf{DB} \cdot \vec{e} + \Delta \cdot \mathsf{DB} \cdot \vec{\mu_i} - \mathsf{DB} \times A \cdot \vec{s}\\ &= \mathsf{DB} \cdot \vec{e} + \Delta \cdot \mathsf{DB} \cdot \vec{\mu_i} \end{align*} $$Now, you can round this result to closest multiple of $\Delta$, then divide the resulting vector by $\Delta$ to get the retrieved data.
Observation
- The time consuming part is $\mathsf{DB} \times A$. However, this is independent to the query and the secrete key. Hence it is used as hint.
- Since we only need one final entry, instead of decrypting the whole answer vector, we can instead use a single row of $H$ and a single $\mathbb{Z}_q$ in $\mathsf{ans}$ for the decryption.
DoublePIR
Upon decrypting the desired value, the client needs the $j$ th element from $\mathsf{ans} \in \mathbb{Z}_q^{\sqrt N}$, and the $j$ th row of $\mathsf{H} \in \mathbb{Z}_q^{\sqrt N \times n}$. DoublePIR, as suggested in its name, uses another SimplePIR to retrieve these $n + 1$ values. However, with some changes.
Observe that after running SimplePIR once, $\mathsf{ans}$ and $\mathsf{H_1} := \mathsf{H}$ are all in $\mathbb{Z}_q$. However, the initial input DB for SimplePIR should be in $\mathbb{Z}_p$. Hence, a decomposition function $\mathsf{Decomp}: \mathbb{Z}_q \mapsto \mathbb{Z}_p^{\kappa}$ is used prior to the second SimplePIR, where $\kappa = \lceil \log q/ \log p\rceil$. Now, we treat the decomposed hint $\mathsf{Decomp}(\mathsf{H_1}^T)$ as the new database, we can compute the new hint $\mathsf{H_2} = \mathsf{Decomp}(\mathsf{H_1}^T) \times A_2$, which will be downloaded by the client.
However, we cannot pre-compute the hint for the $\mathsf{ans}$ vector. Hence, the solution is to create the hint ($\mathsf{H_3} = \mathsf{Decomp}(\mathsf{ans}^T) \times A_2$) and ask the client to download it together with the other $n+1$ values.
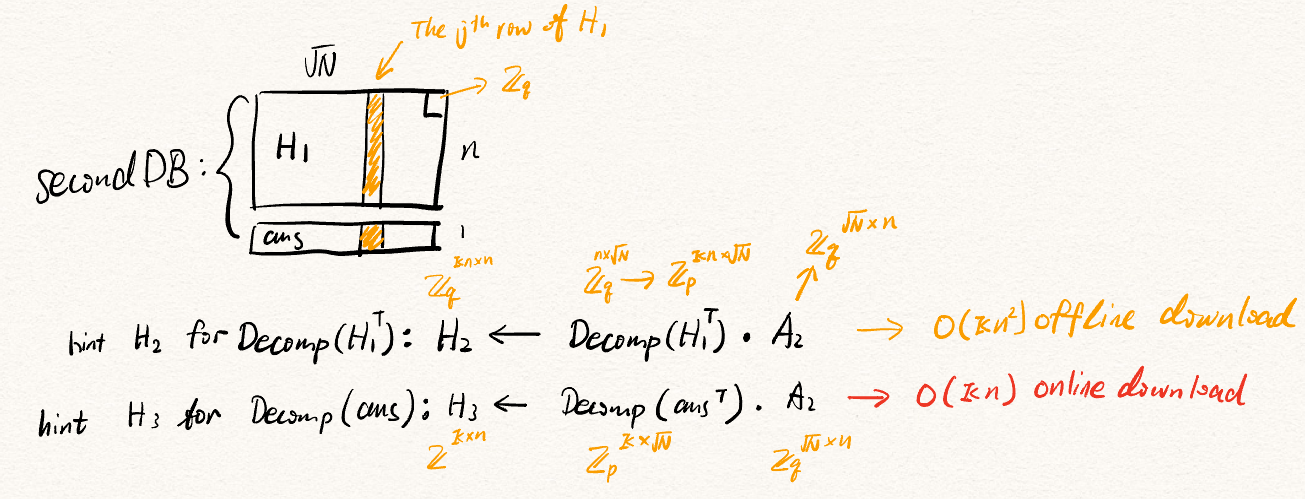
Observation
- The new hint $\mathsf{H_2}$ is only affected by $\kappa$ and $n$. So the hint size won’t change when $N$ changes.
Limitations
Extension to large entries
- In SimplePIR, hint size is $n \cdot \sqrt{dN}$ many $\mathbb{Z}_q$. For a $1\mathsf{GB}$ database with $4 \mathsf{KB}$ entires, this means $N = 2^{18}, d = 4096 \cdot 8 / 9 \approx 3641, n = 1024$, hint size is roughly $121\mathsf{MB}$
- In DoublePIR, hint size is $d \kappa n^2$ many $\mathbb{Z}_q$. Concretely, this means $16 \mathsf{MB}$ of hint for retreving a $9$-bit entry. If we want to support $4 \mathsf{KB}$ (same as small OnionPIR), hint size will be $16 \cdot d \mathsf{MB} = 58256 \mathsf{MB} \approx 56\mathsf{GB}$.
- Also in DoublePIR, the response size is proportional to $d$. Download $d \cdot \kappa (2n+1)$. In the same $4\mathsf{KB}$ setting, this means $114$ MB for download. So the expansion faction is still an important metric.
Client side computation
In the current SimplePIR code base, $A$ is stored and used for creating query. Size of $A$ is same as size of the hint, so in normal setting, 120MB. If we don’t store it, then pseudorandomly generating the matrix $A$ takes about $4.5 \mathsf{s}$, while the server computation is in $110\mathsf{ms}$. If we consider this client work for each retrieval, PRG computation will be the dominant factor. This limintation seems to apears in YPIR as well, whose construction was inspired by SimplePIR and DoublePIR.